はじめに
記述統計を出力する関数はたくさんあるけれど、どれも少しずつもの足りない。
既存のパッケージに敬意を払ったあと、公式の場で発表できるくらいの記述統計表を出力するための関数を作る。
目標
今回はサンプルデータであるirisを使って、Speciesごとに4変数の基本統計量を出力する。
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
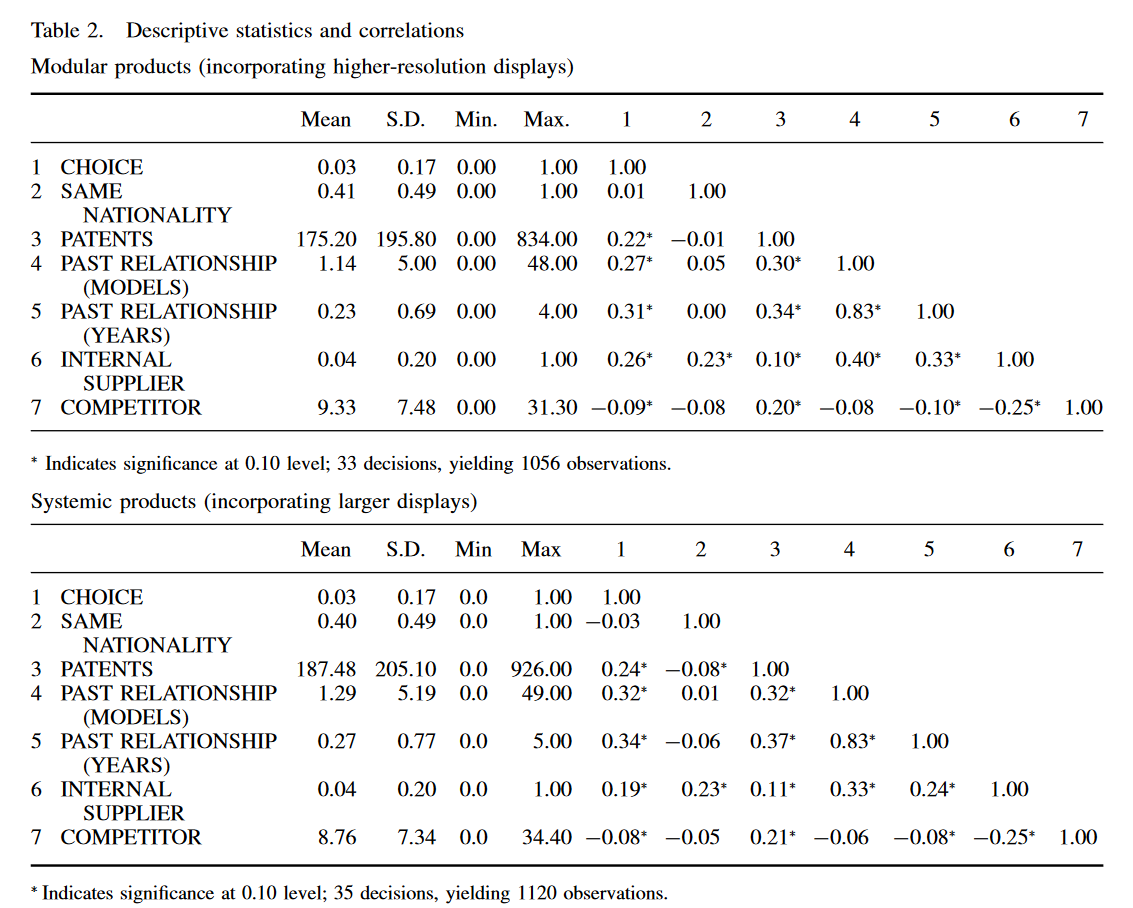
目標は、以下の表のように、グループごとの記述統計表を作ること。 論文の規定という体で大文字小文字の区別や桁数も再現してみたい(右側の相関行列は省略)。
既存のパッケージ
基本統計量を出してくれる関数として、
base::summary()
summarytools::descr()
psych::describeBy()
を確認する。
# パッケージの読み込み :: p_load (tidyverse, summarytools, psych, gt)
base::summary()
とりあえずの確認には便利だけど、標準偏差とサンプル数がない。
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median :5.800 Median :3.000 Median :4.350 Median :1.300
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
Species
setosa :50
versicolor:50
virginica :50
filter()を使ってSpeciesごとに出力することはできる。
%>% filter (Species == "setosa" ) %>% summary ()
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4.300 Min. :2.300 Min. :1.000 Min. :0.100
1st Qu.:4.800 1st Qu.:3.200 1st Qu.:1.400 1st Qu.:0.200
Median :5.000 Median :3.400 Median :1.500 Median :0.200
Mean :5.006 Mean :3.428 Mean :1.462 Mean :0.246
3rd Qu.:5.200 3rd Qu.:3.675 3rd Qu.:1.575 3rd Qu.:0.300
Max. :5.800 Max. :4.400 Max. :1.900 Max. :0.600
Species
setosa :50
versicolor: 0
virginica : 0
psych::describeBy()
まずはそのままのdescribe()。変数が縦にくるタイプ。
%>% :: describe ()
vars n mean sd median trimmed mad min max range skew
Sepal.Length 1 150 5.84 0.83 5.80 5.81 1.04 4.3 7.9 3.6 0.31
Sepal.Width 2 150 3.06 0.44 3.00 3.04 0.44 2.0 4.4 2.4 0.31
Petal.Length 3 150 3.76 1.77 4.35 3.76 1.85 1.0 6.9 5.9 -0.27
Petal.Width 4 150 1.20 0.76 1.30 1.18 1.04 0.1 2.5 2.4 -0.10
Species* 5 150 2.00 0.82 2.00 2.00 1.48 1.0 3.0 2.0 0.00
kurtosis se
Sepal.Length -0.61 0.07
Sepal.Width 0.14 0.04
Petal.Length -1.42 0.14
Petal.Width -1.36 0.06
Species* -1.52 0.07
describeBy()を使うことで、簡単にやりたいことに近づいた。
%>% :: describeBy (iris$ Species)
Descriptive statistics by group
group: setosa
vars n mean sd median trimmed mad min max range skew kurtosis
Sepal.Length 1 50 5.01 0.35 5.0 5.00 0.30 4.3 5.8 1.5 0.11 -0.45
Sepal.Width 2 50 3.43 0.38 3.4 3.42 0.37 2.3 4.4 2.1 0.04 0.60
Petal.Length 3 50 1.46 0.17 1.5 1.46 0.15 1.0 1.9 0.9 0.10 0.65
Petal.Width 4 50 0.25 0.11 0.2 0.24 0.00 0.1 0.6 0.5 1.18 1.26
Species 5 50 1.00 0.00 1.0 1.00 0.00 1.0 1.0 0.0 NaN NaN
se
Sepal.Length 0.05
Sepal.Width 0.05
Petal.Length 0.02
Petal.Width 0.01
Species 0.00
------------------------------------------------------------
group: versicolor
vars n mean sd median trimmed mad min max range skew kurtosis
Sepal.Length 1 50 5.94 0.52 5.90 5.94 0.52 4.9 7.0 2.1 0.10 -0.69
Sepal.Width 2 50 2.77 0.31 2.80 2.78 0.30 2.0 3.4 1.4 -0.34 -0.55
Petal.Length 3 50 4.26 0.47 4.35 4.29 0.52 3.0 5.1 2.1 -0.57 -0.19
Petal.Width 4 50 1.33 0.20 1.30 1.32 0.22 1.0 1.8 0.8 -0.03 -0.59
Species 5 50 2.00 0.00 2.00 2.00 0.00 2.0 2.0 0.0 NaN NaN
se
Sepal.Length 0.07
Sepal.Width 0.04
Petal.Length 0.07
Petal.Width 0.03
Species 0.00
------------------------------------------------------------
group: virginica
vars n mean sd median trimmed mad min max range skew kurtosis
Sepal.Length 1 50 6.59 0.64 6.50 6.57 0.59 4.9 7.9 3.0 0.11 -0.20
Sepal.Width 2 50 2.97 0.32 3.00 2.96 0.30 2.2 3.8 1.6 0.34 0.38
Petal.Length 3 50 5.55 0.55 5.55 5.51 0.67 4.5 6.9 2.4 0.52 -0.37
Petal.Width 4 50 2.03 0.27 2.00 2.03 0.30 1.4 2.5 1.1 -0.12 -0.75
Species 5 50 3.00 0.00 3.00 3.00 0.00 3.0 3.0 0.0 NaN NaN
se
Sepal.Length 0.09
Sepal.Width 0.05
Petal.Length 0.08
Petal.Width 0.04
Species 0.00
不要な列を削除して表を扱いやすくしてみる。
<- iris %>% describeBy (iris$ Species, mat = TRUE # 行列形式で出力 <- tab[, names (tab) %in% c ("group1" , "mean" , "sd" , "min" , "max" )]
group1 mean sd min max
Sepal.Length1 setosa 5.006 0.3524897 4.3 5.8
Sepal.Length2 versicolor 5.936 0.5161711 4.9 7.0
Sepal.Length3 virginica 6.588 0.6358796 4.9 7.9
Sepal.Width1 setosa 3.428 0.3790644 2.3 4.4
Sepal.Width2 versicolor 2.770 0.3137983 2.0 3.4
Sepal.Width3 virginica 2.974 0.3224966 2.2 3.8
Petal.Length1 setosa 1.462 0.1736640 1.0 1.9
Petal.Length2 versicolor 4.260 0.4699110 3.0 5.1
Petal.Length3 virginica 5.552 0.5518947 4.5 6.9
Petal.Width1 setosa 0.246 0.1053856 0.1 0.6
Petal.Width2 versicolor 1.326 0.1977527 1.0 1.8
Petal.Width3 virginica 2.026 0.2746501 1.4 2.5
Species1 setosa 1.000 0.0000000 1.0 1.0
Species2 versicolor 2.000 0.0000000 2.0 2.0
Species3 virginica 3.000 0.0000000 3.0 3.0
Speceiesのsetosaだけ取り出して、細部を再現してみようとするけど、gt()に渡すと1列目が消えたり面倒になったのでここで撤退。
%>% filter (group1 == "setosa" ) %>% mutate (Mean = round (mean, 2 ), S.D. = round (sd, 2 ),Min. = round (min, 2 ), # minとmaxは0があって2桁に見えない Max. = round (max, 2 ) # 解決法は後述 %>% select (Mean: Max.) %>% head (4 ) %>% gt ()
5.01
0.35
4.3
5.8
3.43
0.38
2.3
4.4
1.46
0.17
1.0
1.9
0.25
0.11
0.1
0.6
関数を自作する
論文の表を再現するためにtidyverse::summarise()とgt()を使って関数を作ってみる。
まずは、across()を使ってすべての変数の統計量を出す。 このタイミングで、基本統計量の厳密な表記も指定しておく。
%>% summarise (across (.cols = where (is.numeric), # 数値型のすべての変数について .fns = list (Mean = ~ mean (.x, na.rm = TRUE ), # 今回は欠損値ないけど S.D. = ~ sd (.x, na.rm = TRUE ),Min. = ~ min (.x, na.rm = TRUE ),Max. = ~ max (.x, na.rm = TRUE )),.names = "{col}-{fn}" ) # "列名-関数名"の形式で列名を作る %>% round (2 ) %>% # 小数点以下2桁に format (nsmall = 2 ) # 0も表示させて見た目も2桁に
Sepal.Length-Mean Sepal.Length-S.D. Sepal.Length-Min. Sepal.Length-Max.
1 5.84 0.83 4.30 7.90
Sepal.Width-Mean Sepal.Width-S.D. Sepal.Width-Min. Sepal.Width-Max.
1 3.06 0.44 2.00 4.40
Petal.Length-Mean Petal.Length-S.D. Petal.Length-Min. Petal.Length-Max.
1 3.76 1.77 1.00 6.90
Petal.Width-Mean Petal.Width-S.D. Petal.Width-Min. Petal.Width-Max.
1 1.20 0.76 0.10 2.50
pivot_loner()で表に。
%>% summarise (across (.cols = where (is.numeric), .fns = list (Mean = ~ mean (.x, na.rm = TRUE ), S.D. = ~ sd (.x, na.rm = TRUE ),Min. = ~ min (.x, na.rm = TRUE ),Max. = ~ max (.x, na.rm = TRUE )),.names = "{col}-{fn}" ) %>% round (2 ) %>% format (nsmall = 2 ) %>% pivot_longer (cols = everything (), # 全ての列を縦に names_to = c ("variable" , "stat" ), # variableとstatに分ける names_sep = "-" # -でわける
# A tibble: 16 × 3
variable stat value
<chr> <chr> <I<chr>>
1 Sepal.Length Mean 5.84
2 Sepal.Length S.D. 0.83
3 Sepal.Length Min. 4.30
4 Sepal.Length Max. 7.90
5 Sepal.Width Mean 3.06
6 Sepal.Width S.D. 0.44
7 Sepal.Width Min. 2.00
8 Sepal.Width Max. 4.40
9 Petal.Length Mean 3.76
10 Petal.Length S.D. 1.77
11 Petal.Length Min. 1.00
12 Petal.Length Max. 6.90
13 Petal.Width Mean 1.20
14 Petal.Width S.D. 0.76
15 Petal.Width Min. 0.10
16 Petal.Width Max. 2.50
pivot_wider()で横に。
%>% summarise (across (.cols = where (is.numeric), .fns = list (Mean = ~ mean (.x, na.rm = TRUE ), S.D. = ~ sd (.x, na.rm = TRUE ),Min. = ~ min (.x, na.rm = TRUE ),Max. = ~ max (.x, na.rm = TRUE )),.names = "{col}-{fn}" ) %>% round (2 ) %>% format (nsmall = 2 ) %>% pivot_longer (cols = everything (), names_to = c ("variable" , "stat" ), names_sep = "-" %>% pivot_wider (names_from = stat, # statを列に values_from = value # valueの値に
# A tibble: 4 × 5
variable Mean S.D. Min. Max.
<chr> <I<chr>> <I<chr>> <I<chr>> <I<chr>>
1 Sepal.Length 5.84 0.83 4.30 7.90
2 Sepal.Width 3.06 0.44 2.00 4.40
3 Petal.Length 3.76 1.77 1.00 6.90
4 Petal.Width 1.20 0.76 0.10 2.50
gt()を使って見た目をより近づけていく。
%>% summarise (across (.cols = where (is.numeric), .fns = list (Mean = ~ mean (.x, na.rm = TRUE ), S.D. = ~ sd (.x, na.rm = TRUE ),Min. = ~ min (.x, na.rm = TRUE ),Max. = ~ max (.x, na.rm = TRUE )),.names = "{col}-{fn}" ) %>% round (2 ) %>% format (nsmall = 2 ) %>% pivot_longer (cols = everything (), names_to = c ("variable" , "stat" ), names_sep = "-" %>% pivot_wider (names_from = stat, values_from = value %>% cbind (num = c (1 : 4 ),.) %>% # 変数番号をつける gt () %>% cols_label (num = "" ,variable = "" ) %>% # 列名を消す tab_header (title = "グループ名" ) %>% # タイトル tab_options (heading.align = "left" ) %>% # タイトルを左揃えに tab_footnote (footnote = paste ("*" ,"サンプル数" , "observations." )) # 脚注
Mean
S.D.
Min.
Max.
1
Sepal.Length
5.84
0.83
4.30
7.90
2
Sepal.Width
3.06
0.44
2.00
4.40
3
Petal.Length
3.76
1.77
1.00
6.90
4
Petal.Width
1.20
0.76
0.10
2.50
完成直前!グループごとに出力できるように微調整して関数にまとめる。
rlangパッケージの記法、絶賛勉強中です。ムズイ。
<- function (df, g) { # gをシンボルに変換 <- rlang:: enquo (g)# グループごとのサンプル数を計算 <- df %>% filter (Species == !! g) %>% nrow ()%>% filter (Species == !! g) %>% # summarise (across (where (is.numeric), list (Mean = ~ mean (.x, na.rm = TRUE ),S.D. = ~ sd (.x, na.rm = TRUE ),Min. = ~ min (.x, na.rm = TRUE ),Max. = ~ max (.x, na.rm = TRUE )),.names = "{col}-{fn}" )) %>% round (2 ) %>% format (nsmall = 2 ) %>% pivot_longer (cols = everything (), names_to = c ("variable" , "stat" ), names_sep = "-" ) %>% pivot_wider (names_from = stat, values_from = value) %>% cbind (num = c (1 : 4 ),.) %>% gt () %>% cols_label (num = "" ,variable = "" ) %>% tab_header (title = rlang:: as_name (g)) %>% # タイトルにグループ名gを指定 tab_options (heading.align = "left" ) %>% tab_footnote (footnote = paste ("*" ,n, "observations." )) # サンプル数nをここで使う
summary_stats (iris, "setosa" )
Mean
S.D.
Min.
Max.
1
Sepal.Length
5.01
0.35
4.30
5.80
2
Sepal.Width
3.43
0.38
2.30
4.40
3
Petal.Length
1.46
0.17
1.00
1.90
4
Petal.Width
0.25
0.11
0.10
0.60
summary_stats (iris, "versicolor" )
Mean
S.D.
Min.
Max.
1
Sepal.Length
5.94
0.52
4.90
7.00
2
Sepal.Width
2.77
0.31
2.00
3.40
3
Petal.Length
4.26
0.47
3.00
5.10
4
Petal.Width
1.33
0.20
1.00
1.80
summary_stats (iris, "virginica" )
Mean
S.D.
Min.
Max.
1
Sepal.Length
6.59
0.64
4.90
7.90
2
Sepal.Width
2.97
0.32
2.20
3.80
3
Petal.Length
5.55
0.55
4.50
6.90
4
Petal.Width
2.03
0.27
1.40
2.50
できた~~~!
おわりに
データフレームを.xlsx出力して、Excelで見た目整えた方が楽なのでは?って思いました(本末転倒)。
summarytools::descr()もpsych::describeBy()も全然使えるけど、やっぱりtidyverseがお気に入りかもしれない。 R上でここまで再現できるんだという学びになりました。
今後は関数をより気軽に作るために非標準評価 (Non Standard Evaluation: NSE) を勉強していきたいです。